【论文精读笔记2】利用文本挖掘估计作者的出生死亡年份
文章目录
这篇文章发表于TKDD,作者的主要工作是提供了一种文本挖掘的方法来估计作者的出生死亡年份。 对于一本书来说,确定它所属的年代以及它作者的身份是一项有趣的工作,其中它的引用和被引能够帮助我们解决这样的问题。 研究实验的对象主要是一些没有标注日期的希伯来语文献。通过对文本中的关键短语、关键词以及引用等信息的利用,作者提出了Heuristic(探索式)和Greedy(贪心的)定律和算法来估计一位作者的出生年份以及死亡年份。
1.来源
[1]Dror Moghaz,Yaakov Hacohen-Kerner,Dov Gabbay. Text Mining for Evaluating Authors’ Birth and Death Years[J]. ACM Transactions on Knowledge Discovery from Data (TKDD),2019,13(1).
完整版本: https://dl.acm.org/citation.cfm?doid=3301280.3281631
2.背景
我们常能发现一些古籍被发现,这些古籍可能对于历史研究非常重要,我们希望知道它的作者。因此通过估计作品完成的时间,就能够推测出完成该作品的作者的人选。从另一个角度,如果知道了作者的出生和死亡年份,我们也能够推算出它的作者。
我们考虑古籍中不同的作者会有相互引用的关系,如果能发掘和分析这些引用,就能够实现我们的目的。这些用于挖掘时序数据的定理是基于两种引用:一种是常规的引用(没有特定词),另一种是具有特定的代表时间的词,比如”Late”(表示对提及的作者的怀念,即提及的作者已经逝世了),”Friend”,”Rabbi”等。
但古籍和一般的学术论文不同。在一篇学术文章中,文档具有良好的结构,想要发现关键词和关键短语更容易;同时,学术论文中的引用格式有明确的规定。对于Rabbinic Responsa( 一本古籍的名称)来说,它使用的引用在结构上比学术论文更为复杂,这就使得检索的难度增大。
具体地说有以下几点原因:
1.犹太教文本并没有类似学术论文中地的引用部分。
2.该文本由三种语言写成,语言的形态较多。
3.自然语言处理需要处理三种语言(希伯来语、阿拉姆语和意第绪语),目前的工作还没有很多进展。
4.许多引用是有歧义的。
5.引用没有标注时间。
6.在引用中有很多由不同的结构和语法风格组成的冗余和半结构化的数据。
目前对于希伯来语文本的研究目前并不算多,Mughaz使用机器学习的方法来分辨作者的写作风格。他的研究基于一系列不同时期的不同作家,这一研究的丰富性让Mughaz将他们集合在一起作为特征,得到函数。词缀集的使用是有效的,词缀时识别任务所使用的主要特征。(还有其他的一些工作在综述中,关于使用引用、用引用估计时间、关键词和信息检索的等,这里不详述了)
3.研究过程
3.1 原理
我们用X表示我们要估计出生/死亡年份的作家,Yi表示其余他引用或者被他引用的作家。加是我们知道所有Yi作家的生平,但并不知道X的。用B表示出生年份,D表示死亡年份,MIN表示一个作家能够开始写作的最小岁数(因为一位作家并不是生下来就会写作),MAX表示一个作家的最大寿命,RABBI_DIS表示一位犹太作家成为father的最小年龄。 MIN、MAX和RABBI_DIS的取值是需要探索的。
对于年份的古籍,作者提出了三种具有不同程度上的确定性的规律:Iron-rules(I)、Heuristic-rules(H)和Greedy-rules(G)。
Iron-rules如其名铁律,就是在任何时间都成立,Heuristic-rules在大部分的时间都成立,一些例外可能会出现,因为MAX、MIN以及RABBI_DIS这些常数的估计值会有误。 Greedy-rules 在实验中是符合的,但是仍然会导致其他文本中的出生死亡年份的估计。
所有的I和H的公式
首先,以下是根据经验推断出的所有的I和H的公式。
D(X) >= MAX(B(Yi)) (0(I))
D(X) >= MAX(B(Yi)) + MIN (1(H))
B(X)<= MIN(D(Yi))-MIN (2(H))
D(X)>= MAX(Y) (3(I))
D(X)<= MIN(D(Yi)) (4(I))
D(X)>= MAX(D(Yi)) (5(I))
B(X)>= MAX(D(Yi))-MAX (6(H))
B(X)>= MIN(B(Yi))-(MAX-MIN) (7(H))
D(X)<= MAX(D(Yi)) + (MAX-MIN) (8(H)).
0.X引用其他人的时候,他在最年轻的被引用者出生前还没有死去。
1.MIN更限定了X的死亡时间 因为MIN是预估出来的人能够开始写作的时间(不是一出生就能写作的)。
2.X的出生日期,一定比被引用的人中最年轻的那位的死亡时间减去MIN要早。
3.如果在特定年限中出现了X的作品,那么他的死亡年龄必然比该年晚(或等于该年)
4.如果引用X的Yi中都明确地说过X去世的话 那么X的死亡时间必然比这群人中最早死去的人要早。
5.如果X引用Yi 其中明确提到了Yi已经逝世,那么X的死亡时间必然比这群人中最晚死去的人还晚。
6.一个作者的出生时间必然晚于引用他并且提到他已经死亡的其他作者中死亡时间最晚者减去MAX。
7. MAX和MIN的差表征的是一个作家能够进行写作的时间段。最早出生的引用X的作家出生后 X出生最多要在MAX-MIN年后(否则最早的出生的引用作家就去世了)。
8.X在引用他的最后一个作家死去后 不可能再活过MAX-MIN年。
ALL函数
ALL函数是使用Iron和Heuristic函数中的所有公式结合起来的。
B min B = MIN ({ B’ (B ≤I (i) ∧B ≤H (i))∀ i} ).
B max B = MAX ({ B’ (B ≥I (i) ∧B ≥H (i))∀ i} ).
D min D = MIN ({ D’ (D ≤I (i) ∧D ≤H (i))∀ i} ).
D max D = MAX ({ D’ (D ≥I (i) ∧D ≥H (i))∀ i} ).
最终对年龄的估计就是B(D)的最大值和最小值的均值。
Greedy Constraints( 贪心约束)
B(X)>= MAX(B(Yi))-MIN (9(G))
B(X)>= MAX(Y)-MIN (10(G))
D(X)<= MIN(D(Yi))-MIN (11(G))
X引用Yi的情况:
B(X)>= MAX(D(Yi))-MIN (12(G))
B(X)<= MIN(B(Yi)) + RABBI_DIS (13(G))
B(X)<= MIN(B(Yi)) + RABBI_DIS (14(G))
X被Yi引用的情况:
D(X)<= MIN(B(Yi)) + MIN (15(G))
D(X)>= MAX(D(Yi))-RABBI_DIS (16(G))
D(X)>= MAX(D(Yi))-RABBI_DIS (17(G))
9.被X提到的Yi名作家 他们中最晚出生的不能超过X可以开始写作的年龄(BX+MIN) 假设在X能够写作时,Yi名作家都还不能写作。
10.X能够写作的年龄不能超过他在Y年写作的年龄,假设X引用的并不都是比他小的作者。
11.X死亡的年份不会超过最早死的那个他引用的作者。
Turning Rules
如果出现计算结果是一个作家活的年纪太大或太小,或者另一个情况是作者的死亡年份大于当前年份,需要对结果进行合理化。
Deinition: D - death year, B - birth year, age = D-B.
Current Year: if (D>2017) {D = 2017}, i.e., if the current year is 2017, then the algorithm cannotresult in a death year greater than 2017.
Age: if (age>101), {z = age-101; D = D-z/2; B = B+z/2}, and if (age < 30), {z = 30 - age; D =D+z/2; B = B-z/2}.
同时假设作者的年龄不能超过101岁,不能低于30岁。
算法
1.清洗数据。
2. 挖掘半结构化的引用,根据关键词确定。
3.将引用的格式规范化。
4.建立索引,计算关键词出现的频次。
5.使用上述的三种算法进行计算。
6.计算三种算法最优值的均值。
3.2 实验
数据集
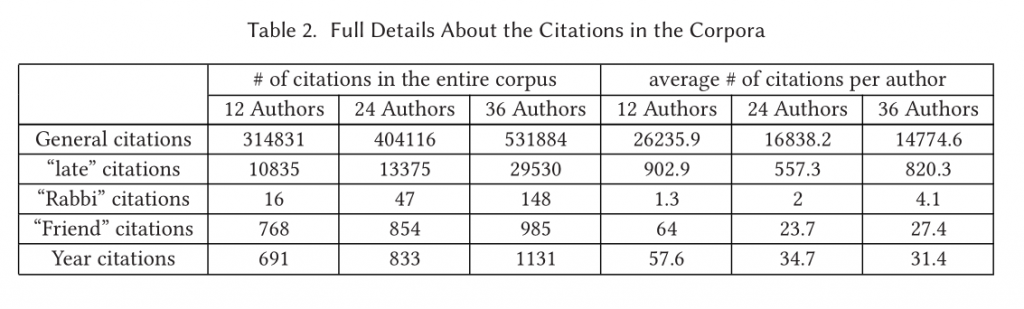
来自Bar-Ilan大学的Responsa项目,包括24111篇Responsa(由36位作者完成)。时间跨度为1765-2015年。这些作品包括很多引用。将这些文章按照作者数量分为了三组(12位作者组,24位作者组合36位作者组)。
由于分为了三组,三组的时间跨度不同,需要将结果标准化进行比较。实验用G算法,I+H算法,以及ALL函数算法对于由或者没有year-feature分别进行了实验。即每一个组需要进行六次实验。
通过实验想要解决的问题
- 哪一种算法是最优的算法?
- 使用turning rules的manipulation的效果是什么?
- 不同的常数会造成怎样的效果?
- 结合出的ALL函数是否起了帮助?
- ALL函数是怎么进行帮助的?
定义
year-feature 使用了作者写某部作品的特定年份得到的结果
composition 使用了turning rules以及其他常数进行估计的结果
constant robustness: robustness包括实验层面上的和提纯层面上的。
衡量算法的好坏是通过鲁棒性。
STDV:standard deviation 标准差,用这个衡量结果的好坏。
3.3 结论
1.从鲁棒性的角度看,Iron 算法,其次是Iron-year(有year feature的)算法,然后是G 算法,最差的是G-year算法。
2.当观测STDV是,ALL函数的结果具有连续性(当作者越多,STDV降低),这就意味着当我们有更多的作者信息时,一些常数的变化不会影响到最终结果。I+H算法就没有这种连续性。
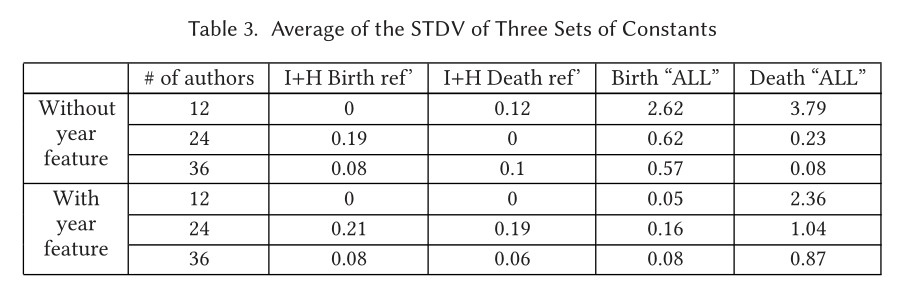
- 结合table4 和5,ALL函数也明显得到了更好的结果,并且随着作者的增加,结果也在变好,STDV在降低。
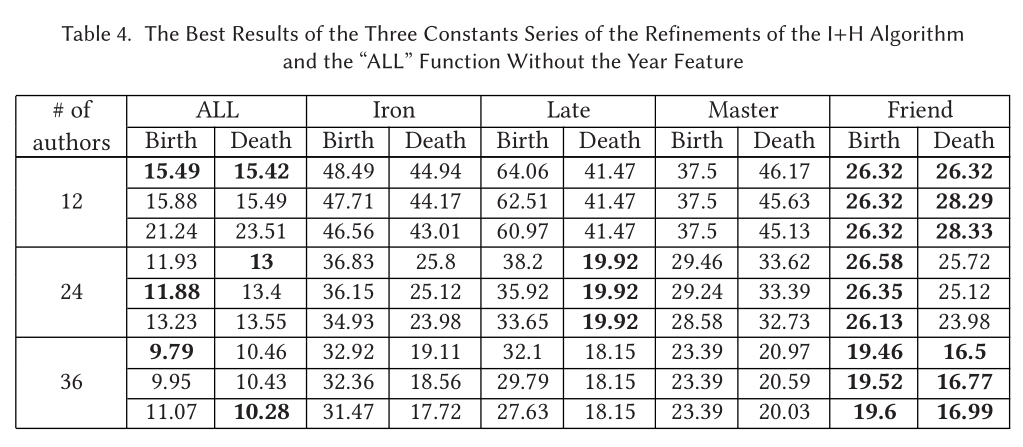
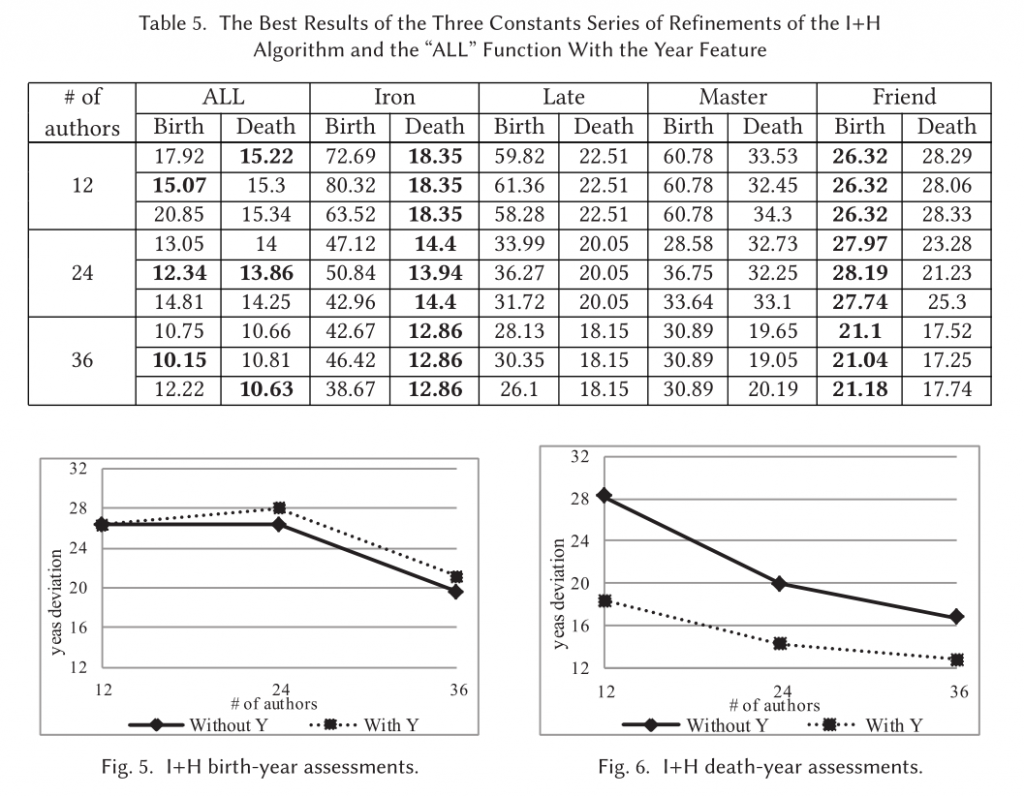
- 对于Greedy算法有和没有year feature的比较,越多作家数量,估计出生年份结果越好,但估计死亡年份时,当没有使用year feature,同样具有相同的趋势,当使用了year feature时,就不具有这样的趋势了。
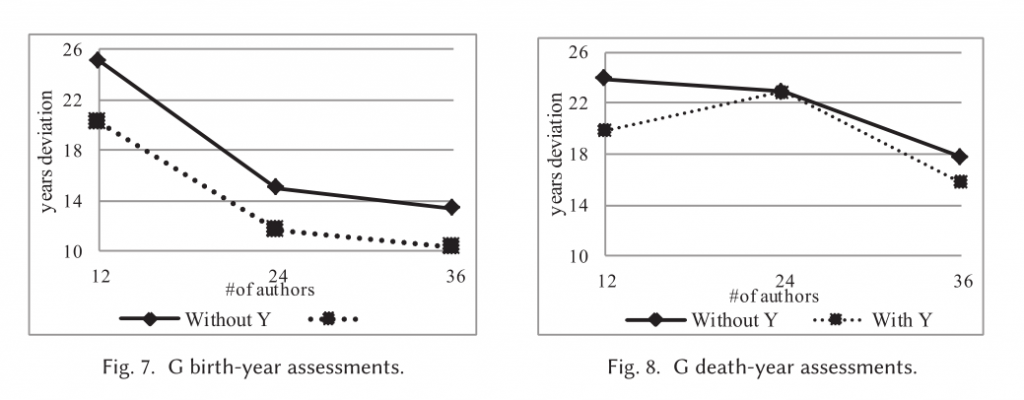
论文中还提出了很多结论,以上只阐述了其中的几条,整个实验的总结如下。
整个实验的总结
从稳定性的角度来说,ALL函数时最好的。ALL具有连续性,当作者的数量越多,结果越好。对于估计死亡年份来说,ALL函数使用year feature的实验结果最好。对于估计出生年份来说,ALL函数没有year feature的实验结果最好。综合来看,ALL函数是最优,因为他良好的连续性、稳定性和结果质量。
3.4 评估
和之前的研究的对比
table11和12显示了ALL函数相较于其他函数的提升。

Mughaz et al的结果比较: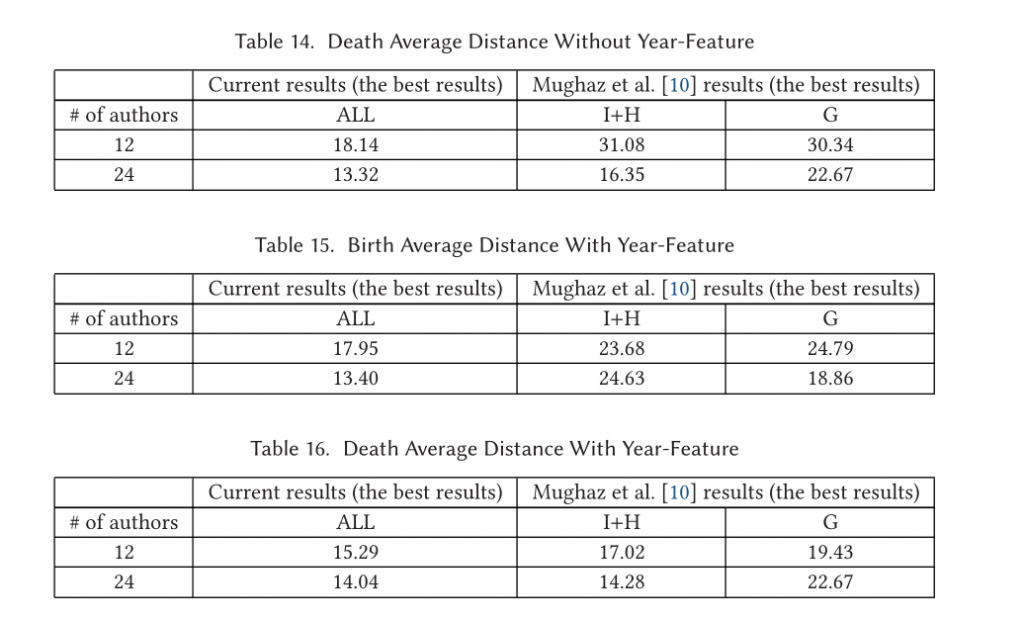
未来的研究
- 测试以上提出的定律的新的组合,比如说将关键词组合在一起的结果。
- 更新相应的规则,生成新的规则。
- 考虑古籍中更多的关键词,比如事件、人名等。
- 用更多的资料对算法进行探究。
- 测试为什么这几种算法会给出更多的值为正的差(预估的比实际的更高)
- 通过更改上界,测试我们还能够获得多大的提高,并将其应用于更古老的作者的语料库中。
4.贡献
- 标准化了选取不同数量作者得到的结果,对于年龄预测结果的比较更加准确。
- 在前人研究的基础上,提出了更准确预测的算法,同时分析了算法的稳健性、对于算法中涉及到的关键词和常数的选取等。
最后一点小感想:
算是看的第二篇数据挖掘方面的,感觉很多还是没有完全读懂。还有一个体会是看TVCG多了,感觉再看B类的语言好像确实没有顶刊精炼(会写论文好重要啊…
关于算法部分,我的一个疑问在于,为什么没有给出具体的实现算法,比如说ALL函数到底是怎么计算的(遍历吗? 作者完全没有给出一行代码。另外还有一点,我认为这篇文章的数学公式里面应该把引用和被引用两种关系区分开来,用Yi表示其他作者(不区分引用和被引用关系)使读者在阅读的时候会有一点错乱。
原文作者: Ruoting Wu
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议