文本数据的聚类分析综述
文章目录
一、引言
聚类分析是一种无监督学习方法,在模式识别中,对于给定的数据样本,类别标号已知的情况下,分类问题通过训练,使得能够对未知类别的样本进行分类。而现实世界中,相当多的数据是没有已知类别的,它们的类别缺失或者需要大量的人工标注才能获取类别。为了发现数据的内在知识、检测并分析异常点和从数据中提取模式,聚类分析是非常重要的。
聚类分析依据相似性,将给定数据样本划分成若干个类别,相似性越高的两个物体划分为同一类,最终会将数据形成若干个簇,簇与簇可根据它们的形状、大小和密度等有所区别。
生活中的多个方面聚类都能够辅助模式识别和数据挖掘。在产品市场上,聚类可以基于用户的购买对商品进行聚类,使得市场营销人员能够利用这些知识开发有针对性地计划;在城市规划上,聚类可以将相似性高的区域进行划分,为土地建设提供选址方案等。
随着全球信息化的不断发展,大量文本数据隐含着潜在的信息和知识。文本数据是一种非常常见的非结构化数据,针对文本数据的聚类应用领域也很广泛。在信息检索方向,文本聚类可对搜索引擎进行聚类,提升用户获取信息的精确度;在信息推荐方向,聚类还可以提取出热点主题或发现事件、自动归档文本并帮助完善文本可视化。
实现文本聚类主要由三个步骤组成:1.文档的表示(提取文档特征并对特征降维处理);2.文本聚类算法的选择和应用;3.评估文本聚类算法的有效性。三个步骤将在接下来的4章中进行详细的探讨。
二、文本数据的特征提取
计算机难以直接对字符串文本进行处理,需要将实际的文字转化成数值型数据。对文本本身来说,它具有一些显式的特征,如字数、词频、停止词数量、单词平均长度等。为了实现文本的聚类,上述的特征需要进行处理和调整,按照某种完整的模型对文档进行数值化或向量化。
当前的主要的文档模型可被分为五个类别:布尔模型、向量空间模型、概率模型、统计语言模型和分布表示模型。
(一)布尔模型
布尔模型具有简洁的形式,容易理解。它的基础是集合论和布尔代数。我们考虑单词在文档中出现或缺失时,一个文档能够用二进制向量表示。
(二)向量空间模型
向量空间模型是将文档表达为向量空间的一个矢量或点,向量空间的维数是词的数量。在向量空间的文档向量的长度是由出现的词和词的权重共同决定的[1]。在向量空间中,单词的顺序并不被考虑,这种方法也称为词袋表示方法(Bag of Words)。它是一种简单、经典的表示方法,但它对出现在文本中的词无法判定其重要性的差异,导致准确率不高。
1983年,Salton等提出了扩展布尔模型[2],它结合了布尔模型和向量空间模型,并表现出检索性能的提升。
1986年,TF-IDF被提出[3],这种表示改进了词袋表示法,每个单词的词频都由逆文档频率(IDF)规范化。在单词集合中,出现频率更高的项权重更低,降低了常用词在文档中的重要性,保证后续文档聚类的结果更受文档出现频率低的词的影响。
(三)概率模型
概率模型中,文档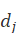 )与查询
)与查询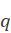 )的相似度有如下关系:
)的相似度有如下关系: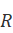 )表示相关文档集,
)表示相关文档集,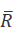 )表示的补集。
)表示的补集。
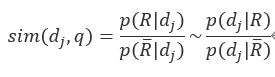
对文档而言,根据独立性假设,文档的各个词相互独立,用 表示词可得到:
表示词可得到:
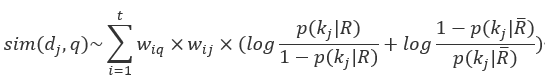
其中词权重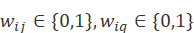 。
。
用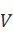 )表示相关文档数,
)表示相关文档数,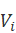 )表示包含索引词
)表示包含索引词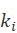 )的文档数,相关文档中)的分布
)的文档数,相关文档中)的分布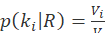 , 不相关文档中)的分布
, 不相关文档中)的分布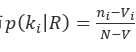 ),
),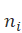 )表示包含索引词的文档数。
)表示包含索引词的文档数。
则可推出:
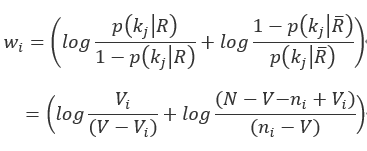
概率模型的优点在于,文档可以按照相关概率递减顺序来计算秩;但概率模型需要把文档分为相关和不相关的两个集合,未考虑到单词的频率,没有权重系数[4]。
(四) 统计语言模型
统计语言模型(Statistics Language Models)是基于统计学和概率论对语言进行建模的,主要思想是语言是字母表上的概率分布,该分布表示一种可能性:即任何一个字母序列成为该语言的一个句子。这一分布就是语言的统计语言模型。目前较流行的统计语言模型是n元模型(N-gram),表示一个词的出现与否和其前面的n-1个词有关。
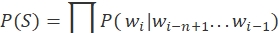
(五)分布表示模型
分布式表示模型不仅考虑将单词符号化,还考虑将语义信息融入到词表示中。 1954 年,Harris提出了分布假说( distributional hypothesis)上下文相似的词,其语义也相似[5],这一假说为语义信息的融入提供了理论基础。
分布式表示根据任务、算法的区别,可被分为基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示。在基于聚类的分布表示中,较典型的算法为布朗聚类方法(Brown clustering),在第四章会具体介绍该算法。
三、样本的相似性度量
文本聚类根据不同的粒度可以分为文档、段落、语句或者单词的聚类。样本在不同的粒度下代表的事物也有所区别,如文档聚类时,每一个样本表示一个文档。对文档进行聚类时,我们需要获知文档样本与样本之间的相似度,需要相似性的度量标准。
相似性度量可使用空间两点的欧式距离、向量内积、余弦相似度、Jaccard相似度等。
相似度的度量会在一定程度上影响算法的效果,目前也有大量的研究针对聚类的相似性度量,如2009年,Luo[6]等人应用了邻居和链接的概念,将全局信息引入到两个文档的相似性度量上,提出了新的相似性度量方式:使用余弦和链接函数组合等,总而言之,相似性度量并不存在最优的方法,需要和聚类算法结合。
四、文本聚类方法
传统的聚类分析算法不仅可以用在文本数据上,其他数据也是通用的。针对文本表示的不同形式,使用的聚类算法也有所区别,文本聚类主要可以分为三类方法:划分聚类方法、层次聚类方法和基于标准参数化模型的方法。
(一)划分聚类方法
划分方法符合我们对聚类的直观感受,将多个样本点组织成多个簇,通常簇的个数会在聚类前被给定,融合了相关领域的主观知识。
划分方法最初指定类别的初始数目,并不断迭代分配样本点,最终收敛时确定所有簇。划分方法运用在文本领域的主要有K-means和K-medoids两种聚类算法。
1. K-means聚类算法
K-means算法最早是从不同的科学领域中提出来的,包括1956年的Steinhaus[7], 和1957年的Lloyd[8],至今已经提出了近60年,但它仍然是目前应用于聚类的算法之一。
K-means通过判断根据平方误差法计算出的目标函数是否达到最优解,而逐步对聚类结果进行优化。在运行前需要指定簇的类别、初始的簇的中心点,在每次迭代中,将每个点分配给中心最近的聚类。中心是群中所有点的平均值,平均点的坐标是簇中所有点上每个维度的算术平均值。
原始的K-means的缺点主要有以下几点:首先,它只考虑了样本点之间的距离,通常结果均为球状簇。若从样本点的密度考虑,以DBSCAN算法为代表的基于密度的方法能够发现任意形状的簇。其次,K值、初始化分方向等均是需要用户给定的,容易陷入局部最优。
2.K-medoids聚类算法
K-medoids聚类算法使用类中的某个点来代表簇,最早提出的K-mediods算法之一PAM(Partitioning Around Medoids) [9]的基本思想就是最初选取k个代表对象作为初始的中心点,依据当前cluster中所有其他点到该中心点的距离之和最小的准则函数,不断迭代找到更好的中心点。
该算法在一定程度上削弱了异常值的影响,但缺点是计算较为复杂,耗费的计算机时间比K-means多。它能处理任意类型的属性,但对异常数据不敏感。
(二) 层次聚类方法
按照层次的聚类方法源于对数据需要组成层次结构的需求,数据需要进行层次结构上的汇总和特征化,因此层次划分方法被引入。层次划分方法可分为凝聚和分裂两种策略。
凝聚策略是将每个样本点在聚类最初都形成一个簇,随着迭代的进行,会将所有簇合并,直到终止条件为止。分类策略与凝聚策略正好相反,它将所有的样本点都看成同一个簇,相当于层次结构的根,将簇不断划分为更小的簇,直到划分的每一个簇都达到凝聚的条件。
以文档聚类为例,凝聚层次聚类方法可以被分为三类[10]:单连接算法(Single Linkage Clustering)、平均连接算法(Group-Average Linkage Clustering)、全连接算法(Complete Linkage Clustering)。
单连接算法的基本思想是两个簇的距离度量是从两个簇中抽取的每一对样本的最小距离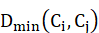 ,一旦最近的两个簇的距离超过某个任意给定的阈值,则算法结束。平均连接的基本算法是两个簇的距离度量是所有样本对的距离的平均值,全连接算法的距离度量则是两个簇所有样本对的最坏情况。
,一旦最近的两个簇的距离超过某个任意给定的阈值,则算法结束。平均连接的基本算法是两个簇的距离度量是所有样本对的距离的平均值,全连接算法的距离度量则是两个簇所有样本对的最坏情况。
在针对文本数据的聚类中流行的层次聚类算法包括:综合的层次聚类方法BIRCH[11],其优点在于能够通过单词扫描获取一个较好的聚类效果,但它只适用于数值型数据;基于质心和代表对象方法的CURE聚类方法[12]从每个类中抽取固定数量、分布较好的点作为代表点,并乘收缩收缩因子,减小噪音对聚类的影响;适用于分类属性层次的聚类算法ROCK[13],和使用动态模型的层次聚类算法Chameleon[14]。
1992年提出的布朗聚类方法[15]是一种针对词汇聚类的算法,它借鉴了层次聚类的凝聚策略,它的输入时一个语料库,语料库是一个词序列,输出是一个二叉树,二叉树的叶子节点是词,中间节点是对应的类别。它的评价函数是对于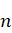 )个连续的词
)个连续的词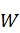 )序列能否组成依据话的概率的对数的归一化结果,评价函数为:$Quality(C)=\frac{1}{n}logP(w_1,w_2…w_n)$。该函数描述了某个词上下文单词对当前聚类中单词的出现的预测程度。
)序列能否组成依据话的概率的对数的归一化结果,评价函数为:$Quality(C)=\frac{1}{n}logP(w_1,w_2…w_n)$。该函数描述了某个词上下文单词对当前聚类中单词的出现的预测程度。
Gil-García[16]等在2006年提出了一个基于图的凝聚层次聚类的通用框架,这一框架指定簇间相似度度量、β-相似度图的子图和覆盖例程,可以得到不同的层次的凝聚型的聚类算法;在2010年[17],作者又提出了针对文档聚类的动态层次算法,该算法在获取和其他传统分层算法相似的聚类质量的前提下,层次结构更小、更利于浏览,可用于创建文档分类法和分层主题检测等模式识别问题。
层次聚类的鲁棒性较强,因为它通常需要比较所有的文档,因此复杂度达到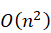 。为了提升层次聚类方法的效率,多种改进方法被提出。如2018年,Zhang等人[18]提出了一个分区合并方案(PMHC)用于快速分层群集,它将数据对象分成适当的组并将它们合并到组中以节省计算成本。
。为了提升层次聚类方法的效率,多种改进方法被提出。如2018年,Zhang等人[18]提出了一个分区合并方案(PMHC)用于快速分层群集,它将数据对象分成适当的组并将它们合并到组中以节省计算成本。
(三)基于标准参数化模型的方法
给定文档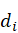 ),获取该文档属于不同簇的概率向量q,也是文档聚类的任务之一。考虑第二章中用统计语言模型表示文档的方式,可假定文档的生成过程是先以一定概率
),获取该文档属于不同簇的概率向量q,也是文档聚类的任务之一。考虑第二章中用统计语言模型表示文档的方式,可假定文档的生成过程是先以一定概率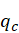 )选择簇
)选择簇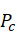 ),然后再按照词
),然后再按照词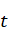 )的概率分布
)的概率分布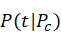 )选择词生成文档d,观测的所有文档在混合模型中被生成的概率为:
)选择词生成文档d,观测的所有文档在混合模型中被生成的概率为:
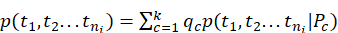
其中为“聚簇参数”,可通过期望最大化算法学习。该方法会陷入局部最优导致收敛速度较慢。
基于EM算法进行聚类的研究主要是基于EM算法对聚类方法的改进和提升,如2005年,Rigutini[19]等人将EM算法与基于信息增益的特征选择技术相结合,该算法只需要少量文档初始化聚类,并且能够正确地提取隐藏在大量未标记集合中的规则。2011年,Kim[20]等人基于EM算法,提出了一种文本文档的主题聚类算法,使用EM方法确保文档被分配给正确的主题,从而收敛到局部最优解,其结果具有较好的性能和可解释性。
EM算法衍生出了主题建模,它是一种对文档进行聚类并提取主题的无监督学习方法,可用来识别大规模文档集或语料库中潜藏的主题信息,广泛应用在文本分类、文本聚类、摘要抽取、情感分析等领域。
主题建模起源于潜在语义分析(LSA)[21],该方法通过奇异值分解,将高维文档向量近似地映射到一个低维潜在地语义空间上,以达到降低文档维数和消除词语存在的同义、多义等问题。在LSA基础上,Hofmann引入了概率统计的思想,提出了概率潜在语义分析模型[22]。然而pLSA模型的参数容易与特定的文档相关,有时会出现过拟合现象,因此,Blei等人在2003年提出了LDA概率主题模型[23],把模型的参数也看作随机变量,引入控制参数的参数,实现进一步的概率化。LDA本质上是一种无监督无指导的机器学习模型,将高维文本单词空间表示为低维主题空间,忽略了和文本相关的类别信息。
(四)其他聚类学习方法
除了上述三点主要的聚类算法之外,针对文本数据的部分其他聚类算法将在本节进行简短的阐述。
模糊聚类需要根据研究对象本身的属性来构造模糊矩阵,并根据隶属度来构造模糊矩阵,最终确定聚类关系。它可允许一个文档属于不同的局促,使得聚类结果更稳定[24]。
半监督聚类是一种更新的研究算法,半监督聚类的核心思想是把半监督学习的思想结合到聚类中,通过少量的标签数据和先验知识提高聚类性能,得到性能更优的结果。在文本聚类中,使用半监督获取少量标签的聚类算法也有部分研究。
Zhang W 等提出了基于频繁项集和相似度计算的最大获取的文本聚类方法[25]。
五、聚类结果的评价
聚类结果并没有没有适用于所有算法的统一的评价指标,聚类算法结果的好坏取决于聚类算法的使用的相似性度量和相应的聚类算法。首先好的聚类的簇需要满足两个特点:簇内高内聚,簇间低耦合。其次,好的聚类能够发现隐含的模式,簇的形状没有较大限制;最后从用户的角度来说,能够产生一个满足用户的聚类结果,结果具有可解释性、可理解性。
(一)分类评价指标
通常,聚类任务可以使用分类任务的数据集(包含分类标签),衡量聚类的质量可以使用分类任务的评价指标。
1.召回率和准确率
对于信息检索的结果,其计算包括了两个指标:召回率(Recall Rate)和准确率(Precision Rate)。召回率表示检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率;准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;F 值为两者的调和平均值。
2.宏平均和微平均
宏平均(Macro-averaging),是先对每一个类统计指标值,然后在对所有类求算术平均值。微平均(Micro-averaging**),是对数据集中的每个实例不分类别进行统计建立全局混淆矩阵,然后计算相应指标[26]。
(二)交叉检验方法
将用于聚类的数据集划分为m个部分,随机使用m-1个部分建立聚类模型,并用剩下的1个部分检验聚类的质量。这一部分可以计算与他们最近形心的距离平方和作为度量,重复m次后,总体质量度量由质量度量的平均值计算出来,对不同的k,可以比较总体质量度量,最终选取最佳拟合数据的簇数[27]。
(三)聚类质量的测定
当有专家构建的基准时,可将聚类模型和基准进行比较,比较时聚类质量度量Q如满足以下4项基本标准:簇的同质性、簇的完全性、碎布袋、小簇保持性,那么可以使用Q进行比较和评估。
当基准不存在时,可以采用轮廓系数对距离进行内部评估。
假设数据集D有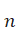 )个样本被分为
)个样本被分为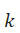 )个类别,则对于任意一个样本
)个类别,则对于任意一个样本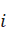 ),计算)与)所在簇中其他对象的平均距离
),计算)与)所在簇中其他对象的平均距离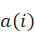 ),)与其他簇的最小平均距离为
),)与其他簇的最小平均距离为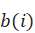 。轮廓系数的定义为:
。轮廓系数的定义为:
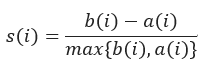
当轮廓系数为越接近1时,包含的簇是紧凑的,当轮廓系数值为负时,这种情况是糟糕的,应该避免。
六、聚类的局限性和挑战
不同的文本数据有不同的特性,目前文本数据聚类的局限性也给文本聚类这一领域带来了新的挑战。
目前文本数据仍存在数据稀疏等问题,文档的词汇可能很多,但这些词汇是相互关联的,数据中主成分的数量远小于特征空间的特征数量。因此上述的所有聚类方法并不能解决所有文本的聚类问题。
近年来社交网络媒体和在线聊天应用创造了大量的文本数据,特别是短文本,短文本表示维数大,如何探索出更有效率、更节省空间的数据表示形式、如何将表示形式与聚类算法更好地结合在一起,是未来仍值得研究的课题。
文本数据也越来越多地出现在异构应用程序中,有效地将基于文本的算法应用于异构多媒体场景是非常关键的。P2P分布式文档聚类算法解决了其中的一些难题[28],但对于开发结合优化技术的新型混合算法的研究仍有很大的需求。近年来的研究热点也集中在高维数据的处理上,不断提高处理速度和规模。
【后记-如果你还能看到这里】
这是模式识别课程的最终提交论文(我靠着这个论文得了98分),找了几十篇论文掐头去尾粗略的看了,还是有很多不懂的地方,但至少对于这个方向有了一个框架上的概念。写综述真的很锻炼人哇…
参考文献
[1] Salton, G. Some experiments in the generation of word and document associations [A].Proceedings of the December 4–6, 1962, fall joint computer conference[C].1962.234–250.
[2] Salton, G.& E. A. Fox.& H. Wu. Extended Boolean information retrieval[J]. Communications of the ACM, 1983,26(11):1022–1036.
[3]Salton, G.&M.J.McGill. Introduction to modern information retrieval[M].New York.The McGraw-Hill Companies,1986.
[4]McCullagh, P. What is a statistical model?[J]. Annals of Statistics,2002,30:1225–1310.
[5]Harris, Z. Distributional structure[J]. Word,1954,10(23):146-162.
[6]Luo, C., Li, Y., & Chung, S. M. Text document clustering based on neighbors[J]. Data & Knowledge Engineering,2009,68(11):1271–1288.
[7]Steinhaus, H. Sur la division des corp materiels en parties[J]. Bull. Acad. Polon. Sci,1956, IV (C1.III):801–804.
[8]Lloyd, S. Least squares quantization in PCM[J].IEEE Trans Inform Theory.1982,28:129–137.
[9]Kaufman,L.&,P.J.Rousseeuw.,Clustering by means of Medoids[J].Statistical Data Analysis Based on the L1–Norm and Related Methods,1987: 405–416.
[10]Aggarwal, C. C.&C.Zhai.A Survey of Text Clustering Algorithms[J]. Mining Text Data,2012: 77–128.
[11]Charikar,M.&C.Chekuri. Incremental clustering and dynamic information retrieval[J]. SIAM J Comput, 2004,33(6):1417-1440.
[12]Guha,S.&R.Rastogi.CURE: an efficient clustering algorithm for large databases[J]. Inf Syst,2003,26(1):35-58.
[13]Dutta,M.&AK.Mahanta.QROCK: a quick version of the ROCK algorithm for clustering of categorical data[J]. Pattern Recognit Letter, 2005,26(15):2364-2373.
[14]Karypi,G.&EH.Han.Chameleon: a hierarchical clustering algorithm using dynamic modeling. Computer,1999,32:68-75.
[15]Brown,P,F&V.J.Della Pietra.Class-Based n-gram Models of Natural Language[J].Computational Linguistics,1992,18:467-480.
[16]Gil-García,J.&M. Badía-Contelles&A.Pons-Porrata. Extended Star Clustering Algorithm[J]. Lecture Notes on Computer Sciences,2003,2905:480-487.
[17]Gil-García,R.&A.Pons-Porrata.Dynamic hierarchical algorithms for document clustering[J].Pattern Recognition Letters,2010,31(6):469-477.
[18]Zhang, Y.& Cheung, Y. A fast hierarchical clustering approach based on partition and merging scheme[A]. 2018 Tenth International Conference on Advanced Computational Intelligence (ICACI).[C].Xiamen,2018.846-851.
[19]Kim, S.& Wilbur, W. Thematic clustering of text documents using an EM-based approach[J]. Journal of Biomedical Semantics, 2012,3(Suppl 3), S6.
[20]Rigutini,L&U.Adegli Studi di Siena.A semi-supervised document clustering algorithm based on EM[A].IEEE/WIC/ACM International Conference on Web Intelligence[C], Compiègne (France): Proceedings of the IEEE/ACM/WI International Conference on Web Intelligence,2005.200-206.
[21]Deerwester,S&S.Dumais.Indexing by latent semantic analysis[J].Journal of the American Society for Informatlon Science,1990,41(6):391-407.
[22]Hofmann,T.Probabilistic latent semantic analysis[A].Proc.of the Conference on Uncertainty in Artificial Intelligence[C].1999:289—296.
[23]Blei,D&A.Ng A.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3:993—1022.
[24]C. Borgelt and A. Nurnberger.Fast Fuzzy Clustering of Web Page Collections[A].Proc. of PKDD Workshop on Statistical Approaches for WebMining(SAWM)[C],Pisa(Italy) 2004.
[25]Zhang,W.&T.Yoshida.Text Clustering Using Frequent Itemsets[J]. Knowledge-Based Systems,2010,23(5):379-388.
[26]Yang Y. An evaluation of statistical approaches to text categorization[J]. Information retrieval, 1999, 1(1-2): 69-90.
[27]Han,J&M.Kamber.数据挖掘:概念与技术(原书第3版)[M].北京:机械工业出版社.2012.
[28]Judith, J.E.&J.Jayakumari.Distributed document clustering algorithms: a recent survey[J].Int. J. Enterprise Network Management,2015,Vol. 6, No. 3:207–221.
原文作者: Ruoting Wu
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议