Boosting提升
文章目录
什么是Boosting
TODO
Boosting的两种方法
AdaBoost算法
Gradient Boost
Gradient Boost Decision Tree(GBDT)
在每个树节点中找到最佳分割点非常耗时,而且会消耗内存
Boosting框架
XGBoost
LightGBM
基于histogram
leaf-wise


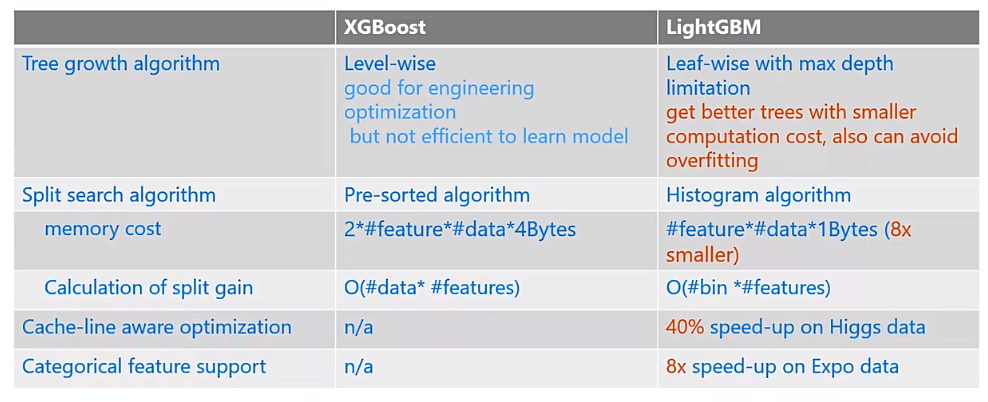
直方图优化:基于分桶,减少内存的使用,正则化不容易overfit
控制max_depth来控制num_leaves
num_leaves=2^max_depth
lightGBM控制num_leaves,而不是树的最大深度,因为lightGBM不会生成满二叉树,因此通过控制num_leaves确保树的深度不过大,防止过拟合。
防止过拟合的方法

参数
num_leaves
num_leaves越大,增加了训练集的精确度,但增加了过拟合的几率
num_iterations
Bagging 和 Boosting的区别
Bagging:
- 训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的
- 使用均匀取样,每个样例的权重相等
- 所有预测函数的权重相等
- 各个预测函数可以并行生成
Boosting:
- 每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化,权值是根据上一轮的分类结果进行调整
- 根据错误率不断调整样例的权值,错误率越大则权重越大
- 每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重
- 各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果
参考资料:
1.微软亚洲研究院AI头条分享-Introduction to LightGBM-Taifeng Wang
原文作者: Ruoting Wu
原文链接: https://codingclaire.github.io/2021/04/14/2021-04-14-boosting/
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议