【异常检测5】基于集成学习的异常检测
文章目录
集成学习主要分为三种方法:
1.Boosting(提升):主要包括两种方法AdaBoost和Gradient Boost,其中Gradient Boost方法的代表是梯度提升决策树(GDBT)
2.Bagging: 主要方法有随机森林
3.Stacking
通过集成学习来进行异常检测的方法主要有两种,分别是特征Feature Bagging和孤立森林(Isolation Forest)。
Feature Bagging
Feature Bagging将Bagging的思想应用在特征上。它结合了多个异常检测算法的结果,每个异常检测算法使用的特征都是从原始特征集合中随机选取的特征子集合。每种异常检测的方法会检测出不同的异常点,然后通过异常点分值来对结果进行合并。
基础框架

上述为这种方法的基本框架,每个异常检测的算法会选取每所有样本的d/2-d个特征,d表示原始的特征数,输出不同的分数向量$AS_t(j)$,表示第$t$个方法中,数据集中数据$j$是异常点的概率。由于总共有$T$个方法,那么会有$T$个异常分数向量,最后使用COMBINE函数对向量进行合并,最后生成一个$AS_{FINAL}$向量,表示数据点是异常点的最终的概率。
COMBINE方法
1.Breadth-First 广度优先

2.Cumulative Sum 累积求和

优劣
优势:
feature bagging能够降低方差(bagging方法使用有放回抽样,数据集间会有重复的样本,每个模型之间具有相关关系,设相关系数为$\rho$,模型均值的方差可以被表示为:
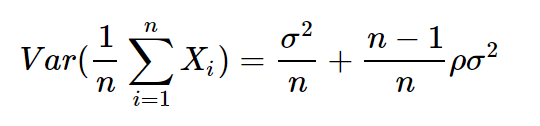
当n增大时,模型整体的方差会趋向于$\rho\sigma^2$,模型方差会降低。
孤立森林(Isolation Forests)
整体思想
假设我们用一个随机超平面来切割数据空间,切一次可以生成两个子空间。然后我们继续用随机超平面来切割每个子空间并循环,直到每个子空间只有一个数据点为止。直观上来讲,那些具有高密度的簇需要被切很多次才会将其分离,而那些低密度的点很快就被单独分配到一个子空间了。孤立森林认为这些很快被孤立的点就是异常点。
孤立森林使用集成方法得到收敛值,将多种切割的方法进行平均,使得结果更为可靠。
孤立树的生成
孤立森林是由t棵孤立的树构成,每个树是随机二叉树,对异常点来说,它会很快地被划分到叶子节点,因此叶子节点到根节点的路径越短,数据可能越异常。在这个过程中,不需要知道样本的标签,可以直接通过孤立森林构造树的过程来判断样本是否异常,所以孤立森林的方法是无监督的。树的构造方法如下:
1)从训练数据中随机选择一个样本子集,放入树的根节点;
2)随机指定一个属性,随机产生一个切割点V,即属性A的最大值和最小值之间的某个数;
3)根据属性A对每个样本分类,把A小于V的样本放在当前节点的左孩子中,大于等于V的样本放在右孩子中,这样就形成了2个子空间;
4) 在孩子节点中递归步骤2和3,不断地构造左孩子和右孩子,直到孩子节点中只有一个数据,或树的高度达到了限定高度。
孤立森林的不同的分支对应于数据的不同局部子空间区域,较小的路径对应于孤立子空间的低维,因此这也是一种基于子空间的方法。
路径长度计算

优劣
优势:
- 计算成本相比基于距离或基于密度的算法更小。
- 具有线性的时间复杂度。
- 在处理大数据集上有优势。
劣势:
- 不适用于超高维数据,每次随机选取维度,如果维度过高,则会存在过多噪音。
原文作者: Ruoting Wu
原文链接: https://codingclaire.github.io/2021/05/23/2021-05-23-anomaly-detection-5/
许可协议: 知识共享署名-非商业性使用 4.0 国际许可协议